Todo empezó cuando decidí crear un filtro de mediana para vídeo, el cual por ejemplo FFMPEG no incluye...
Pero empecemos por el principio... ¿En que consiste el filtro de mediana? Pues es un filtro de reducción de ruido para imagenes en el que para cada pixel, se busca junto a sus pixeles cercanos el que tenga el valor de la mediana.
En el caso de las imagenes en escala de grises es muy sencillo determinar este valor, pues solo tienen un canal con un brillo que pasa de 0 (negro absoluto) a 255 (blanco absoluto), pero en el caso de las imagenes a color, lo que hice fue sumar los valores r+g+b para obtener una luminancia aproximada sin hacer demasiados calculos, y es que uno de los problemas del filtro de mediana para imagenes es que es bastante lento.
Filtro de la mediana en acción: (Abrir imágenes para ver mejor)


Pues teniendo esto en cuenta, me puse a implementar mi código para calcular la mediana en imágenes RAW (RGB) en lenguaje C. Una vez que para cada pixel he obtenido el array con su valor y el de sus cercanos, para obtener la mediana hay que ordenarlos. Tras probar varios algoritmos de ordenación (no todos) el que mejor funcionó fue el insertion sort, y es que aunque suele ser malo ordenando arrays grandes, funciona bien cuando estos son pequeños (ej: en la mediana de 5x5 solo hay 25 elementos) y aunque tal vez no sea el mejor, era suficiente.
Pues tras compilar mi código con optimizaciones de compilador al máximo, y al ejecutarlo usando los 8 cores de mi Intel i5 de 8ª generación (8 hilos), los resultados con un video en HD (1280x720) de 300 frames fueron bastante lentos... La mediana de 3x3 no llegaba a 22 fps, y la de 5x5 que era la que más me interesaba no llegaba a 11fps. Esto en uno de los procesadores más actuales.
 Pues iba a dejarlo así como estaba, cuando revisando las caracteristicas de mi portatil, recordé que contaba con una GPU NVIDIA MX130, que aunque es normalilla, nunca había llegado a programar sobre GPU y tenía curiosidad de si era capaz de ejecutar el mismo algoritmo y en cuanto tiempo.
Pues iba a dejarlo así como estaba, cuando revisando las caracteristicas de mi portatil, recordé que contaba con una GPU NVIDIA MX130, que aunque es normalilla, nunca había llegado a programar sobre GPU y tenía curiosidad de si era capaz de ejecutar el mismo algoritmo y en cuanto tiempo.
Pues resulta que sí es posible ejecutar código en la GPU, para ello existen dos opciones: OpenCV (funciona para cualquier GPU de cualquier fabricante) y CUDA (solo para NVIDIA). Yo me decanté por CUDA en esta ocasión.
Pues me puse a aprender un poco sobre como se programaba en CUDA... y tras ejecutar el código equivalente en la GPU los resultados fueron los siguientes:


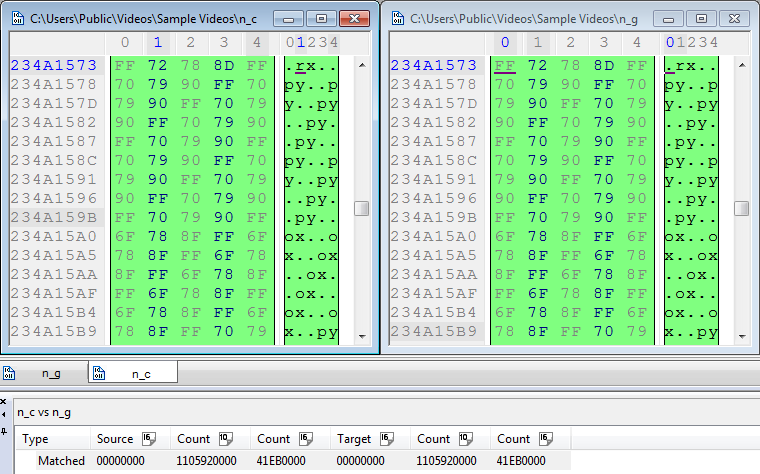
En esta ocasión la GPU no solo era capaz de ejecutar el mismo código, sino que además lo hacía más rápido. ¡Ya alcanzaba los 25 fps! y ademas usando la mediana de 5x5. Si comparamos la salida de ambos proyectos, vemos que es idéntica.
Si entramos en detalles tecnicos, la GPU es capaz de ejecutar hasta 2048 hilos simultaneos repartidos en distintos bloques. En mi implementación usé bloques de 8x8 hilos en los que cada hilo procesaba un único pixel. La imagen original la copio a la memoria global de la GPU (rápida) puesto que cada pixel iba a ser leido por más de 1 hilo, mientras que la imagen resultante era escrita directamente en memoria de la CPU (esto es denominado Zero Copy) puesto que aunque estos accesos son más lentos, esta memoria solo se accedía una vez por pixel para escribir el resultado y evitamos tener que copiar luego la memoria de la GPU a la CPU.