
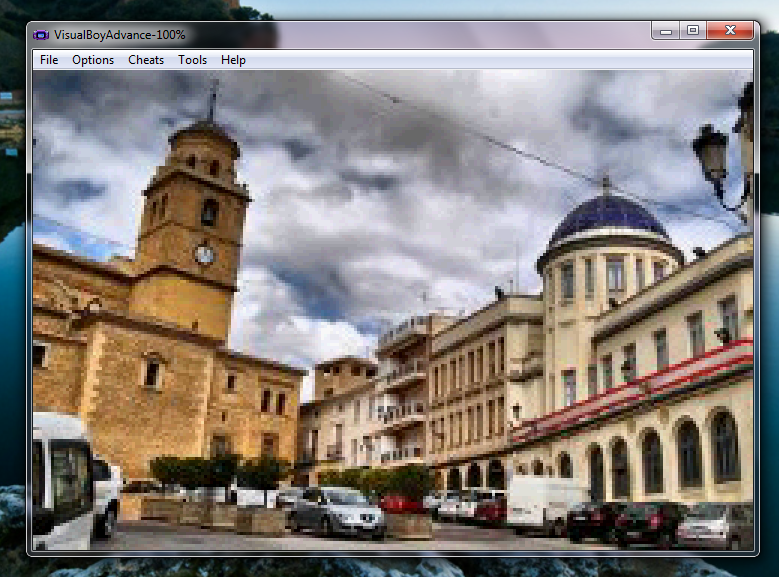
 Bueno, pues como sabreis la GBA no fue muy conocida por la calidad y cantidad de imagenes usadas en juegos. Esto es porque una unica imagen que ocupe toda la pantalla (240x160) sin comprimir ocupa 37 KB en modo 256 colores (baja calidad) o 74 KB a 32.768 colores (alta calidad, apenas usado). Por esto se me ocurrió crear el primer decodificador de ficheros JPG que permiten mostrar estos ficheros de imagen de alta calidad que no ocuparían mas de 15 KB en este formato a resolución nativa en una GameBoy.
Bueno, pues como sabreis la GBA no fue muy conocida por la calidad y cantidad de imagenes usadas en juegos. Esto es porque una unica imagen que ocupe toda la pantalla (240x160) sin comprimir ocupa 37 KB en modo 256 colores (baja calidad) o 74 KB a 32.768 colores (alta calidad, apenas usado). Por esto se me ocurrió crear el primer decodificador de ficheros JPG que permiten mostrar estos ficheros de imagen de alta calidad que no ocuparían mas de 15 KB en este formato a resolución nativa en una GameBoy.Este ROM habría sido un gran adelanto para la consola. Lastima que en 2001 solo era un crio :')
Tenia pensado crear un programa que pudiera adjuntar vuestras propias imagenes al ROM, pero dudo que mas de 1 o 2 personas lo utilizasen, asi que lo abandoné.
En el zip teneis un ROM de 104 KB con 9 imagenes "random" en alta calidad que muestra la presentacion de imagenes junto a los *.jpg utilizados. Si mirais dentro del ROM con un editor hexadecimal comprobareis que estos *.jpg estan contenidos dentro del ROM. A continuación detalles tecnicos:
Resulta que hace unos días encontré el codigo para un decodificador de imagenes orientado a dispositivos embebidos (Como puede ser un marco de fotos digital) el cual era muy simple, y estaba orientado a procesadores con pocas capacidades como el Z80.
Se trata de TJpgDec y lo primero que se me ocurrio al verlo es que podia adaptarlo para hacerlo funcionar en la GameBoy (Plataforma con la cual ya estaba familiarizado) pero antes de intentarlo siquiera me di cuenta de que en la GBC la escasa paleta de colores, resolución, memoria, y potencia del procesador, iban a hacer del trabajo algo inutil.
Viendo esto, informandome sobre las caracteristicas tecnicas de su sucesora, la Game Boy Advance y sobre los distintos modos graficos que tiene, vi que en GBA todo cuadraba, y podria implementar sin problemas el primer decodificador de archivos JPG para GameBoy de la historia, usando para esto el compilador DevKit Advance r5 beta 3 compilando siempre con el maximo de optimizaciones (-O3).
Puestos al trabajo tuve que retocar el codigo de TJpgDec para que en primer lugar, no trabajase con archivos, sino con array de bytes con el contenido de los archivos JPG que se incluirian dentro del ROM, reemplazanto para esto todas las intrucciones como fopen() o fseek() por un codigo que haria su correspondiente funcionamiento en los arrays de bytes.
Cuando ya habia acabado y el codigo me habia compilado con exito vi que salian colores sin sentido y la imagen apenas se reconocia.
De los distintos modos graficos que tiene la GBA yo utilizo el modo 3.
 Como el modo 3 trabajaba con pixeles de 16 bit usé el modo RGB565 del decodificador, pero me di cuenta de que la GBA no usaba RGB565, sino un BGR555 en el que deja sin usar el bit mas significativo de estos 16 bit (Apenas encontré documentación sobre los modos graficos). Por esto, otra vez me toco modificar el codigo de TJpgDec para que convirtiera a el espacio de color de la GBA tal y como se ve en la imagen.
Como el modo 3 trabajaba con pixeles de 16 bit usé el modo RGB565 del decodificador, pero me di cuenta de que la GBA no usaba RGB565, sino un BGR555 en el que deja sin usar el bit mas significativo de estos 16 bit (Apenas encontré documentación sobre los modos graficos). Por esto, otra vez me toco modificar el codigo de TJpgDec para que convirtiera a el espacio de color de la GBA tal y como se ve en la imagen.El programa final compilado al maximo de optimizaciones (-O3) le lleva al procesador de la GBA unos 2-3 segundos para decodificar un archivo, es por esto que mi ROM de prueba se trata de una simple presentación de imagenes en la que el procesador trabaja siempre al 100% para cargar lo antes posible la siguiente imagen













































{kind=link}